

ClickHouse 随心所欲的聚合模型
clickhouse 强大的 MergeTree 系列引擎令人信服,其 ReplacingMergeTree、SummingMergeTree 在数据唯一性和汇总场景中表现非凡。但你是否还有保留最小(大)、平均等预聚合需求,甚至在一个模型中既有唯一性语意也有汇总、最小、最大、平均值语意该如何处理。在 doris 中 Aggregate 数据模型可以轻松解决,那么同为头部 AP 数据库的 clickhouse 是否可以随心所欲的定义聚合模型呢?
一、AggregatingMergeTree
1.1 基本使用
AggregatingMergeTree 表引擎作为 MergeTree 系列引擎也是遵循其家族的基本逻辑的,它能够在合并分区的时候按照预先定义的方式聚合数据。与 ReplacingMergeTree、SummingMergeTree 不同的是表引擎已经内置好了聚合方式,用户只能指定字段在分区合并时对字段进行去重或累加,AggregatingMergeTree 则进一步开发底层给用户,用户需要指定在分区合并时采用何种聚合函数,以及针对哪些字段进行计算,下面是该引擎的使用方式(复刻 doris 官方文档的案例)
drop table if exists tbl_agg;
create table if not exists tbl_agg
(
`user_id` String comment '用户id',
`date` datetime comment '数据灌入日期时间',
`city` String comment '用户所在城市',
`age` Int8 comment '用户年龄',
`sex` Int8 comment '用户性别',
`last_visit_date` AggregateFunction(anyLast,DateTime) comment '用户最后一次访问时间',
`cost` AggregateFunction(sum, Int256) comment '用户总消费',
`max_dwell_time` AggregateFunction(max,Int64) comment '用户最大停留时间',
`min_dwell_time` AggregateFunction(min,Int64) comment '用户最小停留时间'
) engine AggregatingMergeTree()
order by (user_id, date, city, age, sex);AggregateFunction 是 clickhouse 提供的特殊数据类型,它能够以二进制的形式存储中间状态结果。其使用方式也十分特殊,在定义的时候需要提供聚合方式以及数据类型。常用的聚合方式整理如下:
count: 计数非空行数
sum: 累加
max: 最大值
min: 最小值
anyLast: 最后一个非空值
uniq: 去重计数
当然 clickhouse 提供的聚合函数很多,详情可以访问: https://clickhouse.com/docs/en/sql-reference/aggregate-functions/reference
因为 AggregateFunction 是二进制存储的中间结果,我们在插入数据时也需要将明文数据转换为 AggregateFunction 可以接受的数据类型,clickhouse 为每个聚合函数都提供了转换为 AggregateFunction 类型的 *State 函数
insert into tbl_agg
select 10000,
'2017-10-01',
'北京',
20,
0,
anyLastState(toDateTime('2017-10-01 06:00:00')),
sumState(toInt256(20)),
maxState(toInt64(10)),
minState(toInt64(10));
insert into tbl_agg
select 10000,
'2017-10-01',
'北京',
20,
0,
anyLastState(toDateTime('2017-10-01 07:00:00')),
sumState(toInt256(15)),
maxState(toInt64(2)),
minState(toInt64(2));同理我们在查询是也需要特殊的函数将 AggregateFunction 类型转换为明文(类似序列化与反序列区别),而查询时需要使用 *Merge 函数
SELECT
user_id,
anyLastMerge(last_visit_date) AS last_visit_date,
sumMerge(cost) AS cost,
maxMerge(max_dwell_time) AS max_dwell_time,
minMerge(min_dwell_time) AS min_dwell_time
FROM tbl_agg
GROUP BY user_id
ORDER BY user_id ASC
Query id: 30a237df-6018-42fa-a6a9-1d324e21310d
┌─user_id─┬─────last_visit_date─┬─cost─┬─max_dwell_time─┬─min_dwell_time─┐
│ 10000 │ 2017-10-01 06:00:00 │ 35 │ 10 │ 2 │
└─────────┴─────────────────────┴──────┴────────────────┴────────────────┘
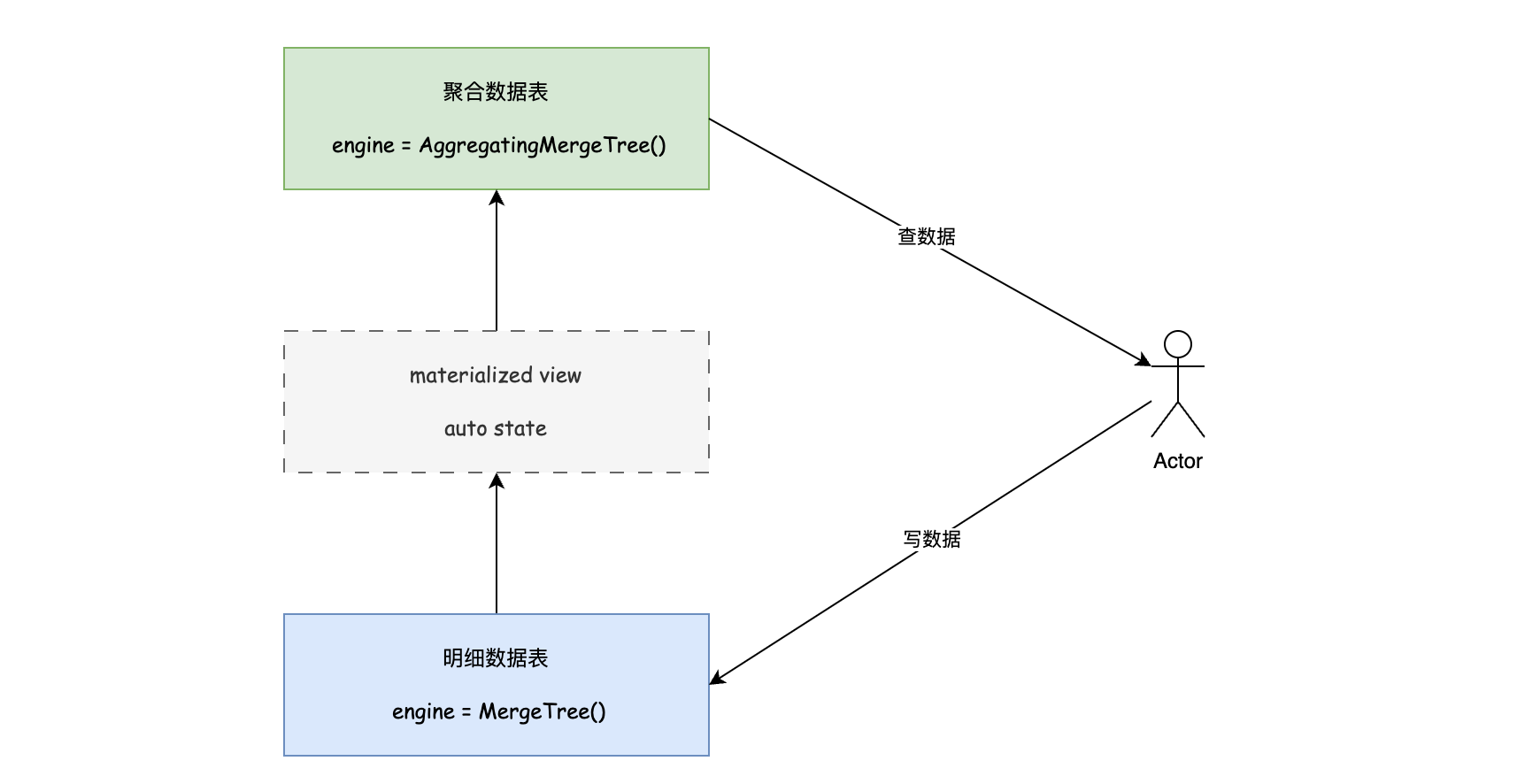
1 row in set. Elapsed: 0.005 sec.看到这里是否觉得这种方式过于繁琐,连正常的数据插入都需要借助 State 函数,那么在升级改造时将寸步难行。好在上面的方式并不是主流的方式,我们可以借助物化视图来屏蔽 State 过程,让数据插入保持原生。
1.2 优化体验
首先我们创建相同结构的普通表作为底表
drop table if exists tbl_agg_basic;
create table if not exists tbl_agg_basic
(
`user_id` String comment '用户id',
`date` datetime comment '数据灌入日期时间',
`city` String comment '用户所在城市',
`age` Int8 comment '用户年龄',
`sex` Int8 comment '用户性别',
`last_visit_date` datetime comment '用户最后一次访问时间',
`cost` Int256 comment '用户总消费',
`max_dwell_time` Int64 comment '用户最大停留时间',
`min_dwell_time` Int64 comment '用户最小停留时间'
) engine MergeTree
order by (user_id, date, city, age, sex);之后我们将 State 过程写入物化视图中
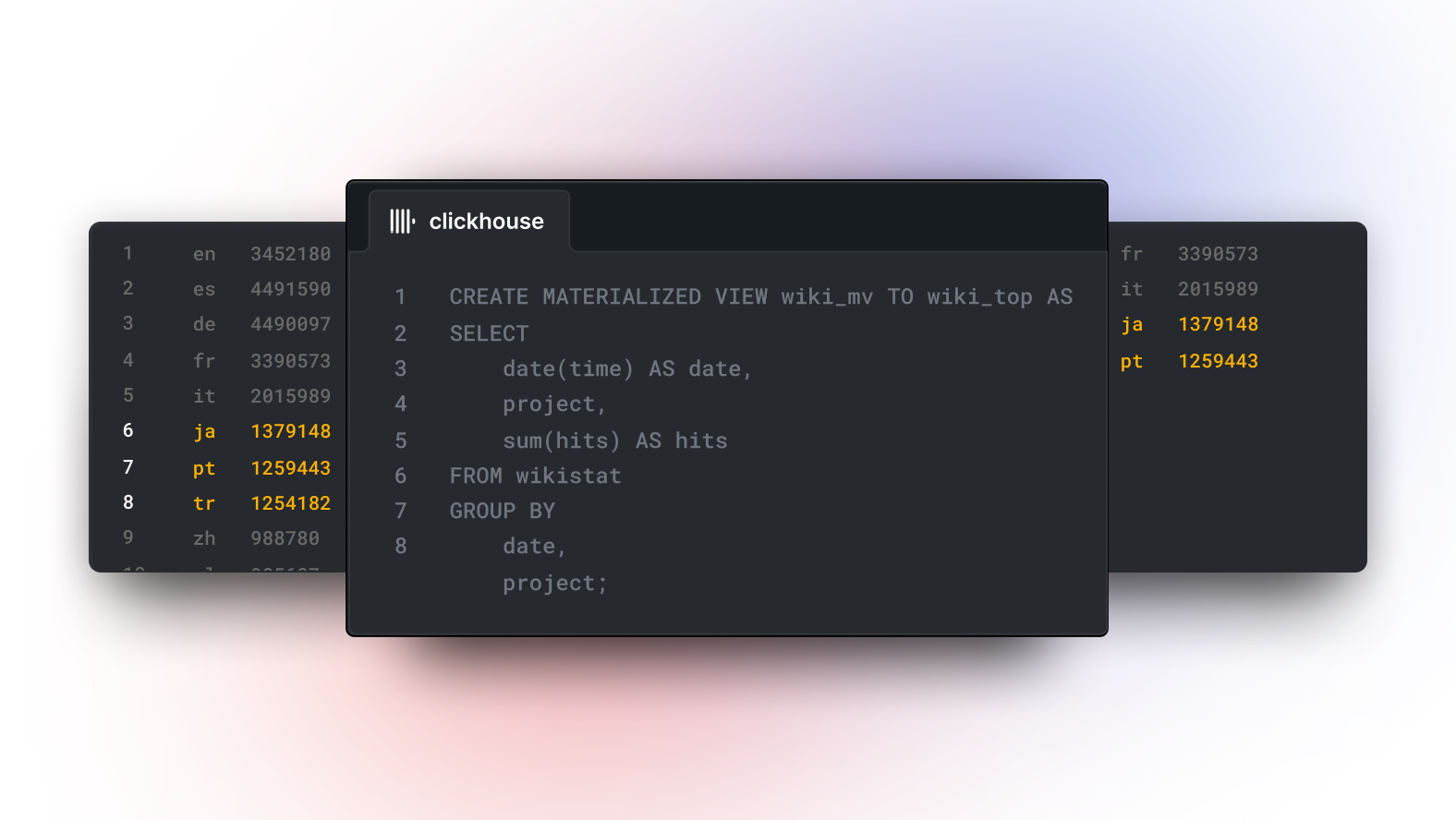
drop table if exists mv_tbl_agg;
create materialized view if not exists mv_tbl_agg to tbl_agg
as
select user_id,
date,
city,
age,
sex,
anyLastState(last_visit_date) as last_visit_date,
sumState(cost) as cost,
maxState(max_dwell_time) as max_dwell_time,
minState(min_dwell_time) as min_dwell_time
from tbl_agg_basic
group by user_id, date, city, age, sex;对用户来说将明细数据优雅的写入底表中,tbl_agg 对外提供查询功能,用户无需关系数据怎么序列化
下面我们只需要假装什么都不知道向明细数据表插入数据
insert into tbl_agg_basic
values (10000, '2017-10-01', '北京', 20, 0, '2017-10-01 06:00:00', 20, 10, 10),
(10000, '2017-10-01', '北京', 20, 0, '2017-10-01 07:00:00', 15, 2, 2),
(10001, '2017-10-01', '北京', 30, 1, '2017-10-01 17:05:45', 2, 22, 22),
(10002, '2017-10-02', '上海', 20, 1, '2017-10-02 12:59:12', 200, 5, 5),
(10003, '2017-10-02', '广州', 32, 0, '2017-10-02 11:20:00', 30, 11, 11),
(10004, '2017-10-01', '深圳', 35, 0, '2017-10-01 10:00:15', 100, 3, 3),
(10004, '2017-10-03', '深圳', 35, 0, '2017-10-03 10:20:22', 11, 6, 6);数据会自动同步到 tbl_agg 中,在查询时我们只需要面向 tbl_agg 此时会比直接查询 tbl_agg_basic 有更高的性能
SELECT
user_id,
date,
city,
age,
sex,
anyLastMerge(last_visit_date) AS last_visit_date,
sumMerge(cost) AS cost,
maxMerge(max_dwell_time) AS max_dwell_time,
minMerge(min_dwell_time) AS min_dwell_time
FROM tbl_agg
GROUP BY
user_id,
date,
city,
age,
sex
ORDER BY user_id ASC
Query id: 6f7fd017-9378-4f42-8c20-56bd711487d1
┌─user_id─┬────────────────date─┬─city─┬─age─┬─sex─┬─────last_visit_date─┬─cost─┬─max_dwell_time─┬─min_dwell_time─┐
│ 10000 │ 2017-10-01 00:00:00 │ 北京 │ 20 │ 0 │ 2017-10-01 07:00:00 │ 35 │ 10 │ 2 │
│ 10001 │ 2017-10-01 00:00:00 │ 北京 │ 30 │ 1 │ 2017-10-01 17:05:45 │ 2 │ 22 │ 22 │
│ 10002 │ 2017-10-02 00:00:00 │ 上海 │ 20 │ 1 │ 2017-10-02 12:59:12 │ 200 │ 5 │ 5 │
│ 10003 │ 2017-10-02 00:00:00 │ 广州 │ 32 │ 0 │ 2017-10-02 11:20:00 │ 30 │ 11 │ 11 │
│ 10004 │ 2017-10-01 00:00:00 │ 深圳 │ 35 │ 0 │ 2017-10-01 10:00:15 │ 100 │ 3 │ 3 │
│ 10004 │ 2017-10-03 00:00:00 │ 深圳 │ 35 │ 0 │ 2017-10-03 10:20:22 │ 11 │ 6 │ 6 │
└─────────┴─────────────────────┴──────┴─────┴─────┴─────────────────────┴──────┴────────────────┴────────────────┘
6 rows in set. Elapsed: 0.008 sec.还可以插入几条数据来观察 tbl_agg 的结果是否符合我们定义的聚合语意
二、SimpleAggregateFunction
对于上面的案例其实在查询时依然不方便需要调用 Merge 函数,本质因为 AggregateFunction 使用二进制存储。如果数据以明文存储是不是就不需要这么麻烦,clickhouse 针对这类场景提供了 SimpleAggregateFunction
drop table if exists tbl_agg_s;
create table if not exists tbl_agg_s
(
`user_id` String comment '用户id',
`date` datetime comment '数据灌入日期时间',
`city` String comment '用户所在城市',
`age` Int8 comment '用户年龄',
`sex` Int8 comment '用户性别',
`last_visit_date` SimpleAggregateFunction(anyLast,datetime) comment '用户最后一次访问时间',
`cost` SimpleAggregateFunction(sum, Int256) comment '用户总消费',
`max_dwell_time` SimpleAggregateFunction(max,Int64) comment '用户最大停留时间',
`min_dwell_time` SimpleAggregateFunction(min,Int64) comment '用户最小停留时间'
) engine AggregatingMergeTree()
order by (user_id, date, city, age, sex);此时该模型就可以视为完美复刻了 doris 的聚合模型,因为插入和查询将变得原生化
insert into tbl_agg_s
values (10000, '2017-10-01', '北京', 20, 0, '2017-10-01 06:00:00', 20, 10, 10),
(10000, '2017-10-01', '北京', 20, 0, '2017-10-01 07:00:00', 15, 2, 2),
(10001, '2017-10-01', '北京', 30, 1, '2017-10-01 17:05:45', 2, 22, 22),
(10002, '2017-10-02', '上海', 20, 1, '2017-10-02 12:59:12', 200, 5, 5),
(10003, '2017-10-02', '广州', 32, 0, '2017-10-02 11:20:00', 30, 11, 11),
(10004, '2017-10-01', '深圳', 35, 0, '2017-10-01 10:00:15', 100, 3, 3),
(10004, '2017-10-03', '深圳', 35, 0, '2017-10-03 10:20:22', 11, 6, 6);
select * from tbl_agg_s;从名字也可以看出,相对 AggregateFunction 就不是那么通用即支持的聚合类型相对较少:
any
anyLast
min
max
sum
sumWithOverflow
groupBitAnd
groupBitOr
groupBitXor
groupArrayArray
groupUniqArrayArray
sumMap
minMap
maxMap
但这些其实已经够用了,同时在上面的聚合场景下 SimpleAggregateFunction 会有更高的性能。
提问: 为什么没有 count
