

Bitmap 在数仓中的应用
一、背景
在数据仓库的日常工作中,我们经常需要面对海量数据的存储和高效查询问题。尤其是,当业务对性能的要求越来越高、数据量持续增长时,传统的处理方式往往显得笨拙而低效。而这时候,Bitmap(位图)作为一种“看似简单却威力强大”的数据结构,逐渐展现出它的价值。简单来说,Bitmap 就像是一种用“0”和“1”记录信息的小工具。它通过位的形式将数据高效地压缩存储,同时支持快速的集合运算,比如并集、交集、补集等。这些特性使得 Bitmap 在高基数去重、行为统计、快速筛选等场景中表现得尤为出色。比如,给定一个数千万级别的用户群,使用 Bitmap 技术可以在几毫秒内完成某些复杂的查询操作,这在传统方法中可能需要数十秒甚至更长时间。 Bitmap 在数据仓库中的应用非常广泛。无论是帮助优化指标计算,还是提升查询性能,它都能够为开发者解决很多头疼的问题。例如,在广告投放场景下,我们需要实时统计某一人群的曝光次数;在用户运营中,我们可能需要高效筛选出符合特定标签的用户群。这些看似复杂的任务,通过 Bitmap,往往能以优雅的方式轻松解决。 这篇文章希望以实际案例为切入点,结合 Bitmap 的原理,聊一聊它在数据仓库中的应用场景和实现方式,帮助大家更好地理解和使用这一实用工具。
二、Bitmap 原理
2.1 基础构成
Bitmap 是一个连续的位数组,数组的每个位置对应一个无符号整数。例如需要存储 1、2、4、5 元素,只需要将这个数组的第 1、2、4、5 位设置为 1 其余位保持为 0 即可,即为011011
2.2 核心操作
2.2.1 交
通过按位与计算两个位图的交集,例如 bitmap1 和 bitmap2 的位图分别是 1010 和 0110,它们的交集为 0010
2.2.2 并
通过按位或计算两个位图的并集,例如 bitmap1 和 bitmap2 的位图分别是 1010 和 0110,它们的并集为 1110
2.2.3 补
通过按位取反计算某个位图的补集,例如 bitmap 的位图是 1010,它的补集位 0101
2.2.4 差
通过按位与非计算两个位图的差集,例如 bitmap1 和 bitmap2 的位图分别是 1010 和 0110,它们的差集为 1000(bitmap & ~bitmap2)
2.2.5 基数
按位计算位图中值位 1 的数量,例如 bitmap 的位图是 1010,它的基数为 2
2.3 应用场景
位图因为其独特的数据结构在大规模数据统计场景有着内存占用低、计算效率高的特点。例如存储 100 万个连续无符号正整数(uint),直接存储大约需要 4MB(100 万 x 4byte),而使用位图只需要100 万位即可,而每位只需要 1bit(8bit = 1byte)大约只需 122KB;同时其按位计算是计算机中效率最高的计算方式之一。 位图的基本操作在生产中应用也是极其广泛的,例如:在用户行为分析中
交:同时满足多个条件的用户集合,对应 sql 中的 and
并:满足任意条件的用户集合,对应 sql 中的 or
补/差:满足条件 A 不满足条件 B 的用户集合,对应 sql 中的 and not 组合
基数:交并补差操作之后统计满足条件的用户个数,对应 sql 中的 count(distinct)
Tip: 从集合的角度来看,补和差的逻辑是一样的。只不过补的逻辑是 AB 两个集合是存在子集的关系,若 AB 不满足父子集关系就是差运算。本质都是从一个集合中扣出另外一个集合中的元素
三、Bitmap 的痛点及其优化
2.3 的例子中特地强调了连续,因为从 Bitmap 基本数据结构可以看出,位图的长度只和最大的元素有关与元素个数无关。如果需要存储一个极其离散的数据集,例如[1,1000000] 位图在需要开辟 100 万个 bit 空间,但实际只存储两条数据,这时候使用位图依然需要 122KB 的空间,但直接存储只需要 2 x 4byte = 8byte 这是其痛点之一。 第二个痛点是只能存储无符号整数,生产中的数据是五花八门的连最常用的字符串都不能处理是会影响它的使用范围的。为此本章节主要是来讨论如何解决或缓解这两个痛点
3.1 RoaringBitmap
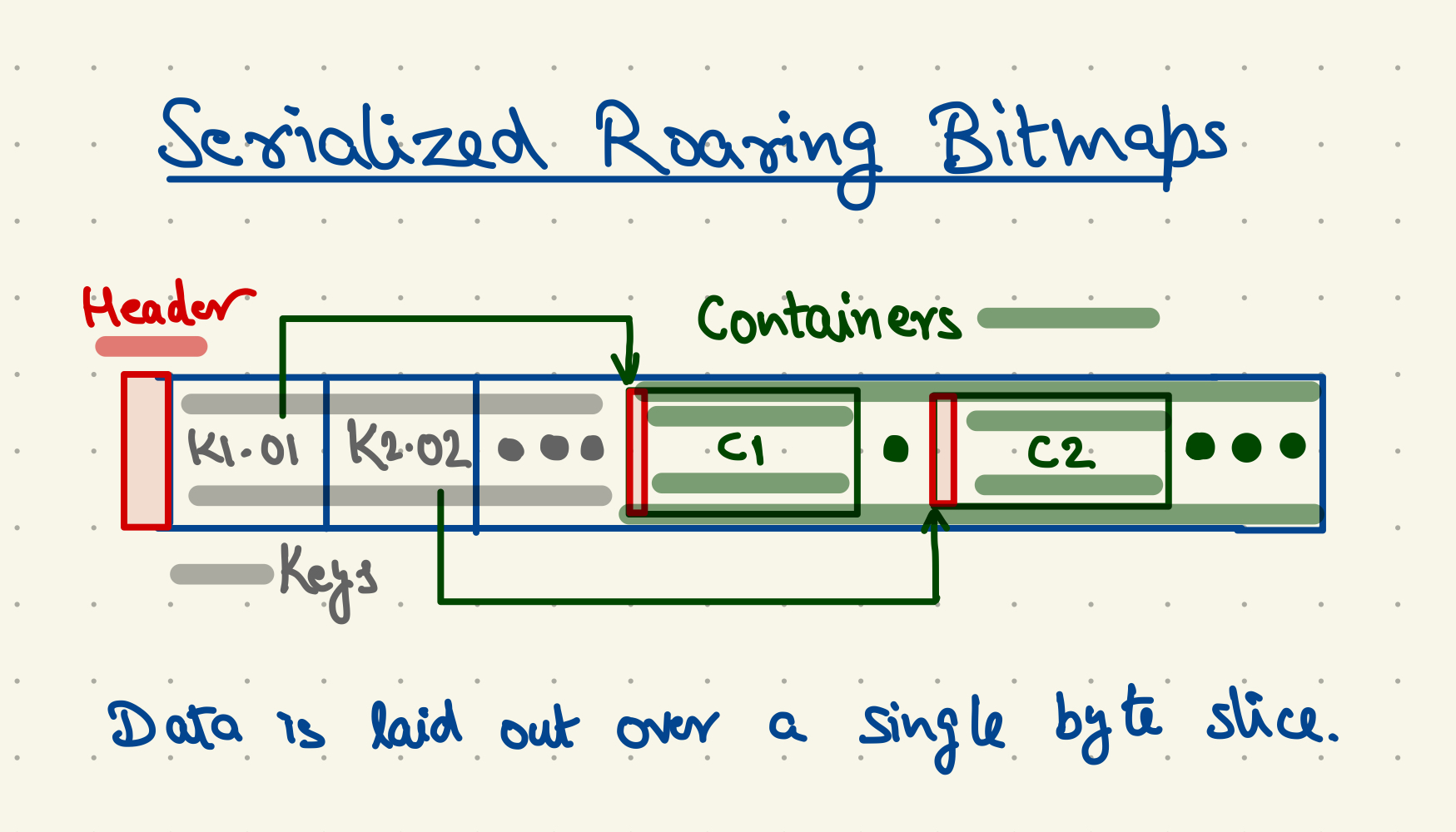
RoaringBitmap 在 bitmap 的基础上通过分块和压缩来表示稀疏或稠密数据的整数集合且每块根据稠密性选择不同的压缩方式,其官网地址如下:https://roaringbitmap.org/ RoaringBitmap 的核心是将一个 32 位的无符号整数分为高 16 位和低 16 位两部分,其中高 16 位作为索引,每个索引对应一个 container 用来存储低 16 位的数据;同时 RoaringBitmap 还会根据数据规模以及稠密程度提供三种 container 实现
- ArrayContainer
- BitmapContainer
- RunContainer 下面通过源码简单的过一下 RoaringBitmap 的实现逻辑
3.1.2 索引逻辑
RoaringBitmap 的底层实现类是 RoaringArray 下面是这个类的核心属性
static final int INITIAL_CAPACITY = 4; // keys 的初始长度
char[] keys = null; // 存储高 16 位的索引值
Container[] values = null; // 存储低 16 位的数据
下面是核心的 add 方法
public void add(final int x) {
final char hb = Util.highbits(x); // 获取高 16 位索引值
final int i = highLowContainer.getIndex(hb); // 通过索引获取容器的索引值
if (i >= 0) { // 容器已经存在
highLowContainer.setContainerAtIndex(i,
highLowContainer.getContainerAtIndex(i).add(Util.lowbits(x)));
} else { // 容器不存在
final ArrayContainer newac = new ArrayContainer();
highLowContainer.insertNewKeyValueAt(-i - 1, hb, newac.add(Util.lowbits(x)));
}}
上面的代码可以看出Container 的默认实现是 ArrayContainer 同时索引的处理逻辑可以这么理解,从 0 到 32 位无符号整数的最大值(42亿左右)按 65536 将元素划分成 65536 份分别存储到 container 中
3.1.3 容器逻辑
ArrayContainer
ArrayContainer 的核心逻辑是通过一个 char 数组按序存储低 16 位的实际值,下面是两个核心参数
private static final int DEFAULT_INIT_SIZE = 4; // 初始容量
static final int DEFAULT_MAX_SIZE = 4096;// 最大容量
所以一定伴随着数组的扩容,对于 DEFAULT_MAX_SIZE 则是当数据规模达到一定程度时存储原始数据将不再有优势需要转换到 BitmapContainer 实现
public Container add(final char x) {
if (cardinality == 0 || (cardinality > 0 && (x) > (content[cardinality - 1]))) {
if (cardinality >= DEFAULT_MAX_SIZE) {
return toBitmapContainer().add(x); // 数据量超过阈值,转换为 bitmapcontainer
}
if (cardinality >= this.content.length) {
increaseCapacity(); // 扩容逻辑
}
content[cardinality++] = x; // 保存低 16 位原始数据
} else {
// 通过二分法查找带插入的位置
int loc = Util.unsignedBinarySearch(content, 0, cardinality, x);
if (loc < 0) {
// Transform the ArrayContainer to a BitmapContainer
// when cardinality = DEFAULT_MAX_SIZE
if (cardinality >= DEFAULT_MAX_SIZE) {
return toBitmapContainer().add(x);
}
if (cardinality >= this.content.length) {
increaseCapacity();
}
// insertion : shift the elements > x by one position to
// the right
// and put x in it's appropriate place
System.arraycopy(content, -loc - 1, content, -loc, cardinality + loc + 1);
content[-loc - 1] = x;
++cardinality;
}
}
return this;
}
BitmapContainer
当数据量超过 4096 时再存储原始数据不管是内存还是计算效率都不占优势,因此将其转换为 Bitmap 存储。需要注意的是 RoaringBitmap 的 Bitmap 相对于位图实现是极其巧妙的。 下面是核心属性以及构造方法
public static final int MAX_CAPACITY = 1 << 16; // 最大容量 65536
final long[] bitmap;
public BitmapContainer() {
this.cardinality = 0;
this.bitmap = new long[MAX_CAPACITY / 64]; // 数组长度 1024
}
MAX_CAPACITY 说明一个 Container 需要存储 65536 个元素(这是低 16 位决定的),但是 BitmapContainer 却使用了 1024 长度的 long 数组来存储,总内存占用固定位 1024 x 8byte = 8KB,下面是最为精彩的添加元素操作
public Container add(final char i) {
final long previous = bitmap[i >>> 6]; // 除 64 找到该值对应的数组位置并获取数据
long newval = previous | (1L << i); // 1L << i 生成只有第 i 位为 1 其余都是 0 的值并与原值做或
bitmap[i >>> 6] = newval; // 替换原值
// 更新基数
if (USE_BRANCHLESS) {
cardinality += (int)((previous ^ newval) >>> i);
} else if (previous != newval) {
++cardinality;
} return this;
}
至于为什么采用 long 来存储同时设计这么复杂的插入逻辑,可以从下面几点思考
- 现代 CPU 的指令集对 64 位(long)数据的处理效率更高
- 使用 long 进行按位操作(如 &、|、~)时,只需一次指令即可处理 64 位,而使用 byte 需要处理 8 次
- 使用 long[] 时,每个元素固定存储 64 位,通过简单的位运算可以直接访问特定位 虽然使用 long 数组在内存使用上不是最优解,但是 BitmapContainer 是在 ArrayContainer 基础上转换过来的,本身已经是一种密集场景,因此使用 long 在计算性能上会有较大的优势,这点额外的内存开销是可以接受的
RunContainer
RunContainer 是一种特殊的容器类型,被设计在用于高效的连续数据存储,使用一个有序数组,存储数值范围的起点和终点,主要的目的是在数据高度连续时,减少内存占用和提高操作效率。 例如:[1, 2, 3, 4, 5, 10, 11, 12] 可以优化为 [(1, 5), (10, 12)] 但是因为数据的离散程度 RoaringBitmap 无法直接控制,因此 BitmapContainer 向 RunContainer 的转变是手动的,在 BitmapContainer 中提供 runOptimize 方法交由使用者自己调用
public Container runOptimize() {
int numRuns = numberOfRunsLowerBound(MAXRUNS); // decent choice
int sizeAsRunContainerLowerBound = RunContainer.serializedSizeInBytes(numRuns);
if (sizeAsRunContainerLowerBound >= getArraySizeInBytes()) {
return this;
} // else numRuns is a relatively tight bound that needs to be exact
// in some cases (or if we need to make the runContainer the right // size) numRuns += numberOfRunsAdjustment();
int sizeAsRunContainer = RunContainer.serializedSizeInBytes(numRuns);
if (getArraySizeInBytes() > sizeAsRunContainer) {
return new RunContainer(this, numRuns);
} else {
return this;
}
}
3.2 Roaring64Bitmap 和 Roaring64NavigableMap
RoaringBitmap 的设计是存储 32 位无符号整数,但是对于大型网站、APP 等其用户 id 规模肯定是超过 RoaringBitmap 的设计范围,因此生产中更多的是使用 Roaring64Bitmap 或 Roaring64NavigableMap 实现,从类名就可以看出来可存储 64 位无符号整数。虽然存储的数据范围不同且实现细节也略有差异,但整体思想都是将数据分为高位和低位,高位作为索引低位存储到 container 中,因此三者的区别主要是对高位索引的处理机制上 Roaring64Bitmap 和 Roaring64NavigableMap 区别如下:
- Roaring64Bitmap 将高 48 位作为索引并存储到 Art 中(The Adaptive Radix Tree),低 16 位存储到 Container 中,Container 的实现与 RoaringBitmap 一致
- Roaring64NavigableMap 将高 32 位作为索引并存储到 NavigableMap 中,具体的实现是 TreeMap 底层是红黑树,低 32 位存储到 Container 中。有自己的实现,感兴趣可以看一下 BitmapDataProvider 的实现类(也是三种)
3.3 拓展任意数据类型
不管是 Bitmap 的哪种实现都只能处理无符号整数,对于字符串的处理可以从下面两种方向去考虑拓展
3.3.1 hash
通过 hash 将字符串转换成无符号整数,但需要考虑 hash 函数的离散型可能得到的集合数据过于离散使用 bitmap 不一定是最佳实践。
3.3.2 row_number
通过 dense_rank() over() 全窗口开窗生成连续序号。这种方案可以处理任意类型的数据同时还可以处理原集合数据过于离散的情况;但是全窗口开窗在超大数据集中效率极低甚至无法完成计算,同时需要额外的 join 操作替换掉原集合数据,这种场景是否需要继续使用 bitmap 有待商榷。
四、生产中的 Bitmap
4.1 集成 Spark/Hive
生产中的 bitmap 通常是使用 UDF 集成到 Spark/Hive 中(下面统称 UDF)。推荐使用 Doris 提供的 bitmap 实现,相对来说比较权威 https://doris.apache.org/zh-CN/docs/ecosystem/hive-bitmap-udf
Tip: doris 的 hive bitmap 在 fe 下面最终生成 jar 相对来说也比较大,可以自己重新起一个专门的 udf 项目对照写一下
4.2 实战
编写一段 shell 脚本用于生成随机的 userid
#!/bin/bash
# 输入参数
MAX_ROWS=$1 # 最大行数
MAX_USERID=$2 # 最大 userid
MAX_PARALLEL=$3 # 最大并行度
# 校验参数
if [[ -z "$MAX_ROWS" || -z "$MAX_USERID" || -z "$MAX_PARALLEL" ]]; then
echo "Usage: $0 <max_rows> <max_userid> <max_parallel>"
exit 1
fi
# 临时目录
OUTPUT_DIR="./output"
MERGED_FILE="./merged_result.txt"
mkdir -p "$OUTPUT_DIR"
# 计算每个子任务分配的行数
ROWS_PER_TASK=$((MAX_ROWS / MAX_PARALLEL))
REMAINING_ROWS=$((MAX_ROWS % MAX_PARALLEL)) # 分配多余的行到最后一个任务
# 打印任务分配情况
echo "总行数: $MAX_ROWS"
echo "最大用户 ID: $MAX_USERID"
echo "最大并行任务数: $MAX_PARALLEL"
echo "每个任务行数: $ROWS_PER_TASK"
echo "多余行数: $REMAINING_ROWS"
# 任务计数器
TASK_COMPLETED=0
# 生成随机行的函数
generate_random_users() {
local task_id=$1
local rows=$2
local output_file=$3
echo "任务 $task_id: 开始生成 $rows 行数据到 $output_file..."
for ((i=1; i<=rows; i++)); do
echo $((RANDOM % MAX_USERID)) >> "$output_file"
done
echo "任务 $task_id: 生成完成!"
}
# 启动子任务
for ((i=1; i<=MAX_PARALLEL; i++)); do
OUTPUT_FILE="$OUTPUT_DIR/task_${i}.txt"
ROWS_TO_GENERATE=$ROWS_PER_TASK
# 最后一个任务需要分配多余的行
if [[ $i -eq $MAX_PARALLEL ]]; then
ROWS_TO_GENERATE=$((ROWS_PER_TASK + REMAINING_ROWS))
fi
generate_random_users "$i" "$ROWS_TO_GENERATE" "$OUTPUT_FILE" &
done
# 等待所有子任务完成
wait
TASK_COMPLETED=$MAX_PARALLEL
echo "所有任务完成!"
# 合并所有文件
echo "开始合并所有任务文件..."
cat "$OUTPUT_DIR"/*.txt > "$MERGED_FILE"
echo "合并完成,输出文件: $MERGED_FILE"
# 清理临时文件
rm -rf "$OUTPUT_DIR"
echo "临时文件已清理!"
生成 1 亿行范围在 0 - 1 千万的 userid
./generate_user_id.sh 100000000 10000000 10
总行数: 100000000
最大用户 ID: 10000000
最大并行任务数: 10
每个任务行数: 10000000
多余行数: 0
任务 1: 开始生成 10000000 行数据到 ./output/task_1.txt...
任务 2: 开始生成 10000000 行数据到 ./output/task_2.txt...
任务 3: 开始生成 10000000 行数据到 ./output/task_3.txt...
任务 4: 开始生成 10000000 行数据到 ./output/task_4.txt...
任务 5: 开始生成 10000000 行数据到 ./output/task_5.txt...
任务 6: 开始生成 10000000 行数据到 ./output/task_6.txt...
任务 7: 开始生成 10000000 行数据到 ./output/task_7.txt...
任务 8: 开始生成 10000000 行数据到 ./output/task_8.txt...
任务 9: 开始生成 10000000 行数据到 ./output/task_9.txt...
任务 10: 开始生成 10000000 行数据到 ./output/task_10.txt...
导入表中
use blog;
create table user_info
(
user_id bigint
) stored as parquet;
create table user_info_txt
(
user_id bigint
) stored as textfile;
load data local inpath '/Users/wjun/tmp/bitmap_data/merged_result.txt' overwrite into table user_info_txt;
-- 数据量扩充 5 倍
insert overwrite table user_info
select tbl.user_id
from user_info_txt t
lateral view explode(array(t.user_id, t.user_id, t.user_id, t.user_id, t.user_id)) tbl as user_id
导入 bitmap jar 并创建 bitmap 相关的函数
add jars hdfs://127.0.0.1:8020/user/hive/jars/hive-bitmap-udf.jar;
create temporary function to_bitmap AS 'com.hive.bitmap.udf.ToBitmapUDAF';
create temporary function bitmap_union AS 'com.hive.bitmap.udf.BitmapUnionUDAF';
create temporary function bitmap_count_v1 AS 'com.hive.bitmap.udf.BitmapCountUDF';
create temporary function bitmap_and AS 'com.hive.bitmap.udf.BitmapAndUDF';
create temporary function bitmap_or AS 'com.hive.bitmap.udf.BitmapOrUDF';
create temporary function bitmap_xor AS 'com.hive.bitmap.udf.BitmapXorUDF';
create temporary function bitmap_to_array AS 'com.hive.bitmap.udf.BitmapToArrayUDF';
create temporary function bitmap_from_array AS 'com.hive.bitmap.udf.BitmapFromArrayUDF';
create temporary function bitmap_contains AS 'com.hive.bitmap.udf.BitmapContainsUDF';
说明:spark 3.5.1 内置了 bitmap_count 这里为了不重名使用 bitmap_count_v1 下面主要演示 bitmap 在计算 uv 的场景实战 正常写法:
select count(distinct user_id) as uv from user_info;
进阶写法:
select count(1) as uv
from (select user_id from user_info group by user_id);
bitmap 写法:
select bitmap_count_v1(to_bitmap(user_id)) from user_info;
即使 user_info 的数据量已经达到 5 亿,但是因为缺少对应的维度(没有 group by)测试结果大概率还是 count(distinct user_id) 最快。还是需要各位在生产环境中去验证,当开发指标时发现 count(distinct user_id) 已经出不来结果并且导致 spark 频繁的 oom 时可以考虑 bitmap 写法
本文的重点是 bitmap 原理以及实现,下一篇文章会重点针对 bitmap 的用法做探讨
讨论:理论上 count(distinct user_id) 都可以优化成嵌套 group by 写法,但是当出现一个查询列表中出现多个字段的 count distinct 嵌套 group by 可能就不是很好实现了
